how camera resolution and distance affects facial recognition accuracy (simplified analysis)
a practical, quantitative guide for privacy curious folks
tldr!
Facial-recognition models such as ArcFace, FaceNet, and modern InsightFace pipelines rely on image detail to extract reliable facial “embeddings” (i.e., mathematical representations of the image of a face). One of the strongest predictors of recognition accuracy comes from a much more fundamental factor: the number of pixels covering the face. This post explains the mathematical relationship between camera resolution, distance, and facial-recognition accuracy, and provides a practical Python tool to measure facial image quality and associated privacy risk.
Finally, this post notes that for most pedestrians walking on the street, 5-6m+ from home Ring cameras, there is likely not enough detail to extract a useful “facial-embedding” - you’re probably good!
update I: Jason Koebler from 404 media recently wrote this article on how Flock “left at least 60 of its people-tracking Condor PTZ cameras live streaming and exposed to the open internet.”
update II: After backlash, Ring cancelled its partnership with Flock Safety in February 2026, following significant public backlash after a Super Bowl ad. The integration never launched, so no Ring customer videos were ever sent to Flock Safety Ring.
1. introduction
Over the past few years, consumer/government smart-camera ecosystems have come under increased scrutiny of violating personal privacy. In September 2025, Amazon announced a range of new 2K and 4K smart-camera devices with new AI facial recognition features that stores and processes the facial embeddings of people passing in front of a Ring camera if the Familiar Faces feature is enabled (requires a compatible Ring subscription, and is not available in Texas, Illinois, Portland, or Quebec due to legislation).
Then, in October 2025, Amazon announced Ring would partner with Flock Safety and share data with the government. To be clear, Amazon is neither the first nor the only company that has released AI facial recognition features - Clearview AI, with a more law-enformence focused user-base, have also come under scrutiny.
Regardless, the fact remains that some individuals may worry that their face may be retained without their knowledge or consent.
The proliferation of facial recognition raises an important question that many reports don’t seem to adequately answer:
Under what conditions can a doorbell or security camera actually capture enough detail to generate a usable facial embedding?
Moreover, a key technical point often missing from the privacy debate:
Whether a given camera can generate a meaningful facial embedding depends largely on distance, resolution, and the number of pixels covering the face.
If a person walks several meters away from a camera that records only 1080px video, their face may occupy too few pixels for any modern recognition algorithm (even a sophisticated one like ArcFace or the systems deployed in commercial products) to reliably extract a face embedding at all. Conversely, a close-range camera with 4K resolution can capture enough detail to produce an embedding even from quick or casual exposures.
In an excellent essay from 2021, Adam Harvey in “What is a face?” notes:
“The best accuracy is obtained from faces appearing in turnstile video clips with mean minimum and maximum interocular distances of 20 and 55 pixels respectively. More recently, Clearview, a company that provides face recognition technologies to law enforcement agencies, claimed to use a 110 × 110 pixel definition of a face… The face is not a single biometric but includes many sub-biometrics, each with varying levels of identification possibilities.”
Understanding these variables is essential for evaluating realistic privacy risks:
- At very close range (1–2 meters), consumer cameras can produce high-quality embeddings.
- At moderate distances, recognition quality depends heavily on resolution, angle, machine learning model, lighting, and sensor size.
- Beyond certain pixel thresholds, a camera simply cannot extract a usable embedding, no matter what software is used. Gen AI “image enhancers” will try to claim differently, but realistically no. By and large, they impute (creating uncertainty), and do not “add” more information. While some super-resolution models trained on face-specific priors can improve recognitions accuracy at low resolutions, they also hallucinate plausible detail rather than recovering real data, so they cannot reliably be used for identification.
The goal in this essay is to use a straightforward geometric framework that helps you estimate the facial pixels captured by cameras. Using just four ingredients^ - 1) camera resolution, 2) field of view, 3) real-world face size, and 4) distance - you can loosely estimate whether a facial recognition system is likely to succeed or fail. Understanding these limits enables us to think more precisely about the technical privacy implications of today’s ubiquitous home surveillance devices.
^ Disclaimer! To clarify, there are more than four ingredients. For example, blur caused by movement would understandably impact facial recognition. Blur, of course, partly results from a video camera’s frame rate. Likewise, low light conditions would also affect the quality of the facial embedding. To keep things simple, I’m using a “naive” framework :P
2. why distance and resolution matter
Facial-recognition systems do not “see” distance directly. What they actually see is the face as a block of pixels. As a person moves farther away from the camera, their face occupies fewer pixels, reducing the amount of detail available for landmark extraction and embedding generation.
More pixels per face → more datapoints per face → better recognition. Fewer pixels → degraded or impossible recognition.
This is why a person standing directly in front of a camera is recognized with high confidence, while someone several meters away may not even be detected.
Here’s a blog post from photographer David Ziser about pixels and portraits

face resolution thresholds
Research (see appendix for further info on methods!) on face-recognition systems shows:
| Face Pixel Height | Expected Recognition Quality |
|---|---|
| ≥ 200 px | Excellent (high stability, robust to disguises) |
| 112 px | Standard threshold for ArcFace |
| 80 px | Noticeable performance drop |
| < 40 px | Recognition typically fails |
Now comes some maths - if you’d rather skip it, go straight to part 4!
3. the mathematical relationship
We can relate camera resolution, field of view, and distance to the face height in pixels using a simple geometric projection formula.
Let:
- \((H_f)\) = real face height (meters), e.g. \(( H_f \approx 0.20\,\text{m} )\)
- \(( R_v )\) = vertical resolution of the camera (pixels), e.g. 720, 1080, 2160
- \(( \theta )\) = vertical field of view (in degrees)
- \(( D )\) = distance from the camera to the subject (meters)
- \(( \text{face}_{px} )\) = face height in pixels in the captured image
Derivation
The vertical span of the scene at distance \(D\) is:
\[ H_{\text{scene}} = 2 D \tan\left(\frac{\theta}{2}\right). \]
This full vertical span is mapped to \(R_v\) pixels, so the meters-per-pixel in the vertical direction is:
\[ \text{meters-per-pixel} = \frac{H_{\text{scene}}}{R_v} = \frac{2 D \tan\left(\frac{\theta}{2}\right)}{R_v}. \]
The face height in pixels is then:
\[ \text{face}_{px} = \frac{H_f}{\text{meters-per-pixel}} = \frac{H_f}{\dfrac{2 D \tan\left(\frac{\theta}{2}\right)}{R_v}} = \frac{R_v H_f}{2 D \tan\left(\frac{\theta}{2}\right)}. \]
Final Relationship
\[ \boxed{ \text{face}_{px} = \frac{R_v \, H_f}{2 D \, \tan\left(\dfrac{\theta}{2}\right)} } \]
This shows:
- \(\text{face}_{px} \propto R_v\): higher resolution → more pixels on the face
- \(\text{face}_{px} \propto \frac{1}{D}\): farther away → fewer pixels on the face
- \(\text{face}_{px} \propto \frac{1}{\tan(\theta/2)}\): narrower FOV (zoomed-in) → more pixels on the face
Interpretation
- Double the distance → half the face pixels
- Double the resolution → double the face pixels
- Narrower field of view → higher pixel density on the face
This explains why a 4K camera can reliably detect faces at much longer distances than a 1080px webcam.
example: 4K camera at different distances
Assume:
- \(H_f = 0.20\) m, see this.
- \(R_v = 2160\) px (4K)
- \(\theta = 90^\circ\)
Using the formula:
| Distance (meters) | Face Pixel Height (px) | Implied Recognition |
|---|---|---|
| 1 m | ~216 px | Excellent |
| 2 m | ~108 px | Usable |
| 3 m | ~72 px | Weak |
| 5 m | ~43 px | Often fails |
4. recognition risk zones (interactive risk heatmap)
The embedded app below shows how different smart-camera devices compare in terms of privacy risk at various distances. Darker/red cells indicate conditions where a camera is more likely to capture enough pixels to generate a usable facial embedding.
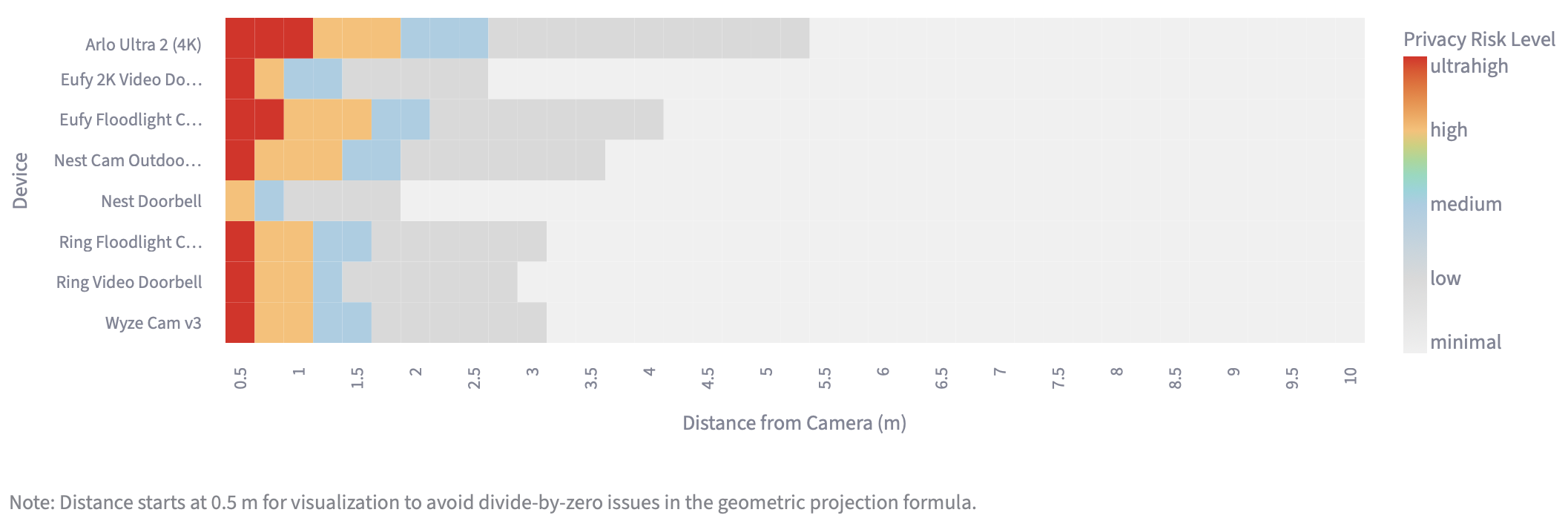
Code available here
5. practical lessons and takeaways
a. Distance acts as a form of compression!
Moving farther from the camera reduces image detail exactly like lowering resolution.
b. Camera resolution directly determines usable recognition range
A 4K camera offers roughly 2× the effective distance of a 1080px camera for the same accuracy.
c. Face pixel count predicts accuracy better than any other variable
This often matters more than:
- model architecture
- training dataset
- pre-processing steps
d. Optical zoom dramatically improves performance
But digital zoom does not…
e. Bad lighting cancels out high resolution
Noise from low light conditions reduces the pixel quality. Higher resolution means more detail, but increasing pixel count shrinks pixel size, reducing light intake and affecting low-light performance. But (!!!) larger sensors in newer cameras enable more pixels without sacrificing size.
6. concluding notes
Facial-recognition accuracy follows a simple rule: the number of pixels covering the face. Knowing this helps privacy-conscious folks estimate when a camera can reliably identify someone, setting realistic expectations for when you should be concerned. For example, a Ring device with 4K resolution, standing more than 5 meters away (like on a house’s front lawn) is probably safe…
The distance from the house (where a camera might be placed) to the street largely depends on local zoning laws. Local codes might require houses to be a certain distance (e.g., 20-40 ft) from the street, which directly determines the minimum front yard depth. In many U.S. suburban areas, houses are probably located 6-12 meters (20-40 ft) from the street, so pedestrians on the street likely don’t have to worry about facial recognition.
7. appendix
methods & assumptions for facial pixel thresholds
a. why face height in pixels?
In facial recognition standards, the term inter-ocular distance (IOD) - the number of pixels between the centers of the eyes - rather than full face height is used. To translate IOD, I assumed the following proportionality:
\[ \text{Face height} \approx 2.5 \times \text{IOD}. \]
Personally, I’m probably closer to 3 than 2.5.
b. Evidence used to define the thresholds
I. High-quality threshold (≥ 200 px face height) High-performance facial recognition typically requires large IOD values:
- ISO and ICAO guidelines for travel documents recommend 90–120 px IOD for high-quality face images.
- Commercial/NIST-linked guidance for FR systems also recommends ≥ 90 px, preferably ≥ 120 px IOD.
Converted via the 2.5× proportion, these imply:
\[ \text{Face height} \approx 225\text{–}300\ \text{px}. \]
To avoid overstating precision, I adopt ≥ 200 px as a conservative indicator that face recognition is likely to be reliable for many modern models.
II. Usable / “medium” threshold (≈ 112 px)
Recent deep face-recognition networks like ArcFace (CVPR 2019), were trained on 112×112 px aligned face crops. This suggests the model expects roughly that pixel scale for stable embeddings.
Thus:
\[ \text{Standard “usable” face height} \approx 112\ \text{px}. \]
III. Low-quality threshold (≈ 80 px)
The choice of 80 px comes from two research lines:
- Low-resolution face recognition surveys indicate that traditional algorithms require 32×32–64×64 px face crops to function, with performance dropping sharply below this range.
- A NIST-affiliated study (Hu et al.) found that systems maintained comparable accuracy as IOD decreased from 60 px to 30 px, but performance severely degraded at 15 px IOD.
Using the 2.5× conversion:
- 30 px IOD → ~75 px face height.
Therefore ~80 px marks a reasonable lower boundary for weak but still potentially recognizable faces.
IV. Minimal threshold (< 40 px)
Several studies show that below this scale, recognition becomes unreliable:
- NIST (Hu et al.) reports severe degradation at 15 px IOD (~38 px face height).
- Zou & Yuen describe faces smaller than 16×16 px as “very-low-resolution,” where recognition algorithms perform poorly or fail entirely.
- 2020 PULSE project by Duke University researchers showed that the restricted perceptual space of a 16 × 16 pixel face image allows for wildly different identities to all downscale to perceptually indifferent images. The work confirmed the technical reality that two faces can appear identical at 16 × 16 pixels, but resemble completely different identities at 1024 × 1024 pixels.
Thus, < 40 px face height is used to indicate minimal recognition capability.
c. Limitations and uncertainty
These thresholds should be interpreted as heuristic ranges:
- Recognition performance depends on lighting, pose, occlusion, compression, and camera optics—not just pixel count.
- Models trained on super-resolution or cross-resolution datasets may recognize faces below these thresholds in controlled settings.
- Many facial recognition models assume a frontal face and simple geometric projection; real-world scenes introduce additional variability.
- Manufacturers typically publish diagonal FOV; vertical FOV values used here are guess-timated from the diagonal spec and each camera’s aspect ratio.